Partnerrollen sind ein wesentlicher Bestandteil der Kundenstammdaten. Sie werden benötigt, um beispielsweise Beziehungen zwischen einzelnen Kunden abzubilden. Beim Order-to-cash-Prozess lässt sich die Relevanz der Partnerrollen anschaulich darstellen: Ein Kunde, der eine Bestellung aufgibt und damit einen Auftrag initiiert, hat die Rolle des Auftraggebers. Dabei ist es zunächst nicht relevant, ob es sich bei dem Auftrag um eine Warenbestellung oder eine Dienstleistung handelt.
Anschließend wickelt das Unternehmen den Auftrag ab, bearbeitet die Bestellung und liefert die Ware schließlich an den Warenempfänger aus, der nicht zwingend identisch mit dem Auftraggeber ist. Daher ist es wichtig, dass die Stammdaten die korrekte Lieferadresse beinhalten. Die Rechnung für den Auftrag erhält der Rechnungsempfänger. Läuft die Rechnungsstellung beispielsweise über eine Shared-Service-Einheit, muss das im Kundenstamm hinterlegt sein. Für die prozesstechnische Verarbeitung des Zahlungseingangs ist die Partnerrolle Regulierer relevant. Hierbei geht es unter anderem darum, Mahnungen an den richtigen Empfänger zu versenden.
Stammdaten bilden Unternehmensstruktur ab
In unserem Fallbeispiel ist die Mustermann AG als Muttergesellschaft der Auftraggeber einer Bestellung. Folglich hat sie die Kontengruppe 0001. Warenempfänger ist die Muster Liefer GmbH (Kontengruppe 0002), während die Muster Zahl GmbH als Rechnungsempfänger fungiert (Kontengruppe 0003). An dieser Konstellation wird deutlich, wie wichtig es ist, dass die Kundenstammdaten eine Konzernstruktur mit mehreren Standorten im System abbilden können.
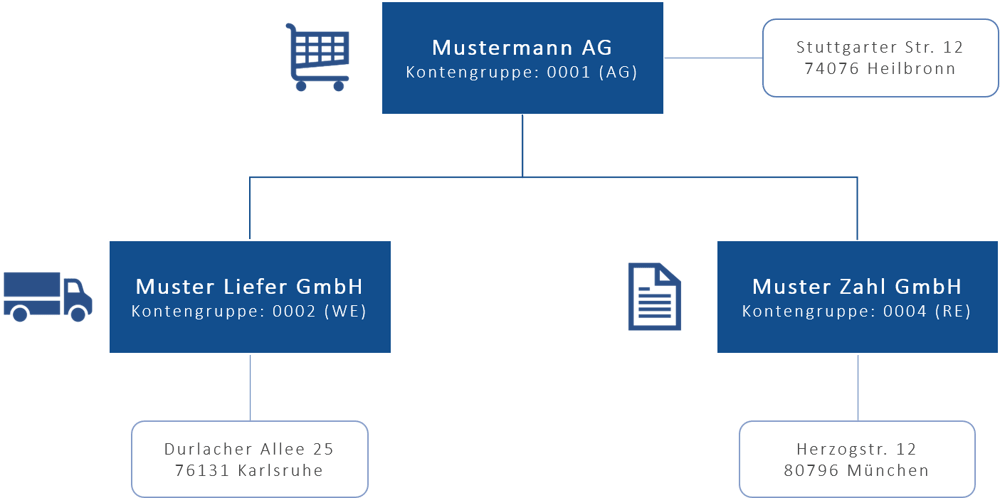
Mit den Partnerrollen lassen sich Beziehungen zwischen einzelnen Kunden abbilden.
Das Standard-Customizing von SAP legt fest, dass ein Auftraggeber die Partnerrollen Auftraggeber, Regulierer, Warenempfänger und Rechnungsempfänger ausprägen muss. Beim skizzierten Beispiel gibt es in der Partnerrolle Warenempfänger eine Referenz von der Muttergesellschaft Mustermann AG auf die Muster Liefer GmbH und in der Partnerrolle Rechnungsempfänger eine Referenz auf die Muster Zahl GmbH. Diese Konstellation lässt sich mit SAP MDG Consolidation abbilden.
Reine Daten für ein intaktes System
Jede Datenmigration hat das gleiche Ziel: ein sauberes System. Um dieses zu erreichen, findet in SAP MDG Consolidation zunächst ein vorgelagertes Data Cleansing statt. So lassen sich Duplikate finden, fehlerhafte Daten bereinigen und sicherstellen, dass keine gesperrten oder für das Löschen markierten Daten in das Zielsystem übernommen werden. In der Regel übernimmt dabei die IT das Extrahieren, Transformieren und Laden (ETL) der Daten vom Bestandssystem in das neue System. SAP MDG Consolidation treibt die Analyse und Bereinigung des eher technischen Data Cleansing in Richtung Business voran, da die Fachabteilungen besser entscheiden können, welche Daten in das Zielsystem überführt werden sollen.
Nach dem Abschluss des Data Cleansing startet dann die eigentliche Datenmigration, die im Falle der Partnerrollen zweistufig abläuft. Aktuell können Referenzen wie Waren- oder Rechnungsempfänger nicht in einem Prozesslauf migriert, sondern müssen gesondert aufgelöst werden. Zunächst werden die Kundenstammdaten migriert, die zweite Phase umfasst das erneute Prozessieren der Daten und das Auflösen der Referenzen in den Partnerrollen.
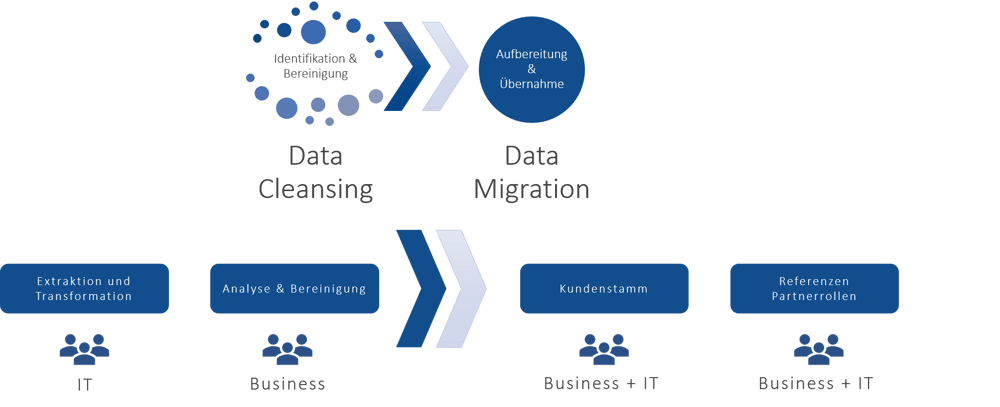
In zwei Schritten zum sauberen System: erst das Data Cleansing, dann die Data Migration.
In sieben Schritten zur Migration
Der Standardprozess in SAP MDG Consolidation setzt sich aus insgesamt sieben Schritten zusammen:
Schritt 1: Data Load
Für den Data Load können ETL-Tools genutzt werden. Alternativ lassen sich die Daten mithilfe einer Standard-App in einen gesonderten MDG-Consolidation-Bereich laden.
Schritt 2: Initial Check
Die initiale Prüfung (Initial Check) ist der eigentliche Start des Migrationsprozesses. Sie dient dazu sicherzustellen, dass die Daten gegenüber dem Customizing im Backend valide sind. SAP MDG Consolidation prüft nicht nur die strukturelle Qualität der Daten, sondern auch, ob alle Pflichtfelder gemäß Customizing befüllt sind. Der Initial Check gibt bereits einen verlässlichen Hinweis darauf, ob die Daten valide genug sind, um sie weiter zu prozessieren.
Schritt 3: Standardisierung
Bei der Standardisierung geht es darum, die Daten anzureichern. Sie bietet viele Möglichkeiten, um externe Services in den Prozess einzubinden. Sinnvoll ist etwa ein Service für die Adressnormalisierung, da erst mit normalisierten Adressen im nächsten Schritt die Matching-Regeln vernünftig greifen, sodass Dubletten gefunden werden können.
Schritt 4: Matching
Das Matching ist eine Duplikatsprüfung. SAP MDG Consolidation fasst die Duplikate in Match-Gruppen zusammen und stellt schon während der Migration sicher, dass das neue System keine Dubletten aufnimmt.
Schritt 5: Best-Record-Calculation
Die Best-Record-Calculation definiert aus den Vergleichsgruppen des Matchings einen Zieldatensatz. Es lassen sich zusätzliche Regeln definieren, um Attribute im Zieldatensatz zu vervollständigen.
Schritt 6: Validierung
Bei der Validierung werden Standard-ERP-Prüfungen ausgeführt. Zudem gibt es die Möglichkeit, die Regeln der zentralen Governance einzubinden und eigenständige BRF+ Regeln zu definieren, die nur im Kontext von SAP MDG Consolidation ausgeführt werden.
Schritt 7: Aktivierung
Der finale Schritt ist die Aktivierung. Hierbei werden die Daten aus dem Arbeitsbereich in den operativen ERP-Bereich, also in die aktiven Datenbestände, geschrieben.
So viel zur Theorie. Wie der zweistufige Prozess mit Migration der Kundenstammdaten und anschließender Auflösung der Referenzen in den Partnerrollen in SAP MDG Consolidation konkret aussieht, beschreiben wir in einem separaten Blogbeitrag.



